Jekyll2024-03-17T22:52:54+00:00https://avikdas.com/feed.xmlAvik DasMy name is Avik Das. I'm a software developer with strong theoretical and mathematical foundations, as well as extensive industry experience. To me, technology is a tool for delivering meaningful products. In my spare time, I enjoy cooking, weightlifting and drawing.
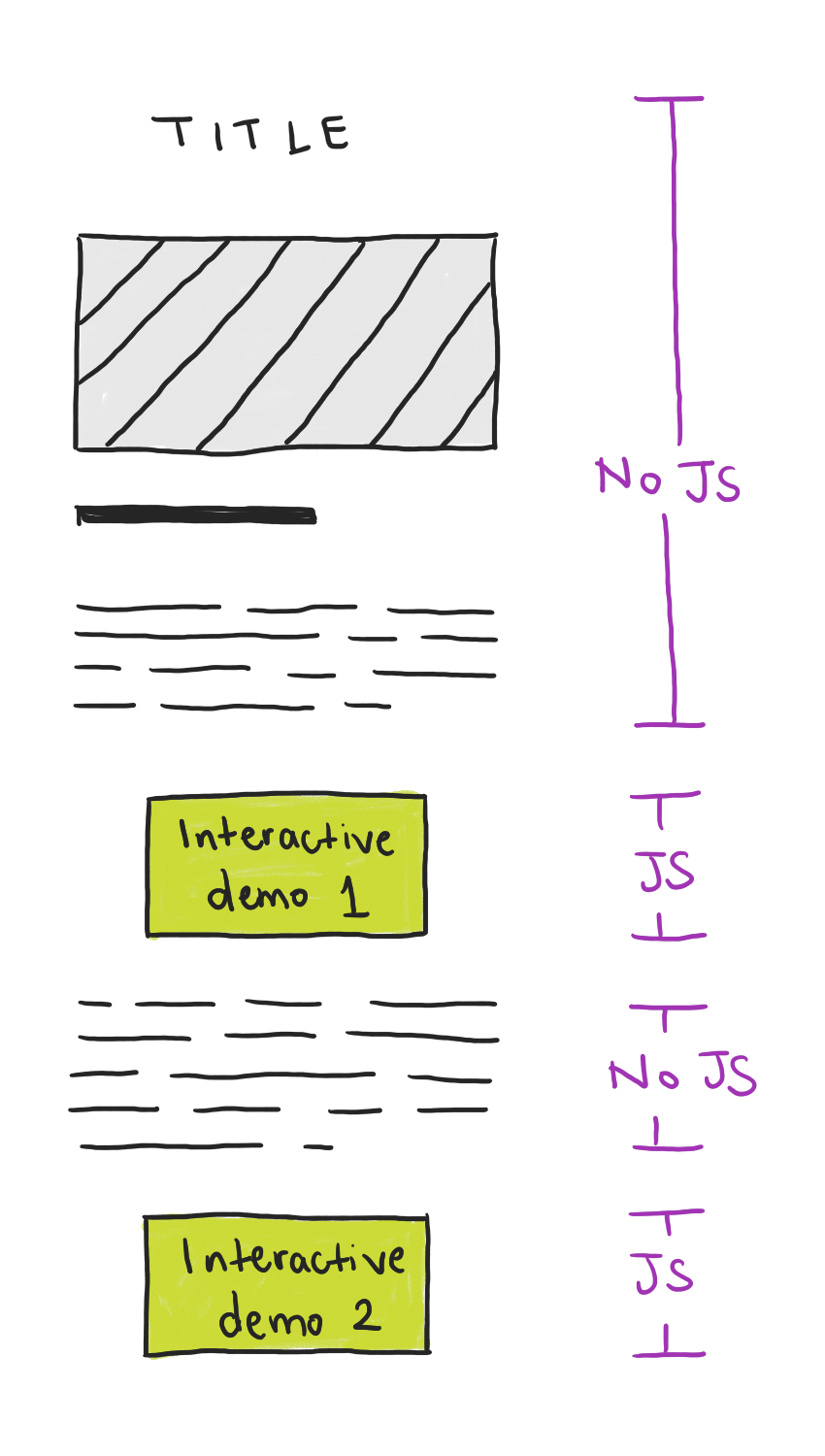
Avik DasInteractive demos using Astro2023-12-30T00:00:00+00:002023-12-30T00:00:00+00:00https://avikdas.com/2023/12/30/interactive-demos-using-astroThis blog is mostly text and images, but I’m a big fan of adding interactive components to make my explanations more effective. See my post on rendering curves in 3D as an example. For those interactive demos, the browser environment, with Javascript for the interactivity, is a fantastic delivery mechanism with wide reach and ease-of-use. Libraries like React make that easy, but a lot of the frameworks and tooling are built around the assumption that the end goal is a single-page app (SPA): the entire page is interactive, and page loads are handled by swapping out what’s on the page. Think Next.js, or the Vue equivalent, Nuxt.
That’s not the way I want my documents to operate. I’m not building web applications, just adding isolated interactive demos to an otherwise static medium. In the last year, I’ve discovered a great framework, Astro, that fits that exact niche. Usually, I prefer to avoid frameworks, but I have been happy enough with Astro to document my experience with it.
The ideal web page for linear, explanatory text with some interactivity sprinkled in
The Astro approach
This is going to sound a bit like I’m writing marketing copy for Astro, but honestly, I found it refreshing that Astro’s philosophy aligned well with mine. Astro promotes content-heavy websites by rendering components on the server, then injecting only the necessary Javascript to make isolated “islands” of interactivity on the client side.
Astro allows you to use any Javascript component library (React, Vue, Svelte, Lit, etc.), or Astro’s own component framework, to build a website. Regardless of what you choose, the Javascript is executed on the server to output static HTML. CSS pre-processors, like Sass, are also supported. The important piece is that no client-side Javascript is shipped. That means, unlike SPA frameworks, you get multiple pages with static HTML and CSS with links between them. At the same time, I still get to use components, allowing me to refactor common elements when coding.
When I use a third-party component library like React, I can optionally mark it as a client component. The component is still rendered on the server, but the component is “hydrated” (brought to life with Javascript) on the client. I can enable this when the page loads or when the server-rendered HTML for the component is scrolled into view (Astro uses the Intersection Observer API). Either way, only the Javascript needed to enable these client-side components are shipped to the browser. This is the Island Architecture. Note that it is possible to share state between islands, which I do in some limited cases.
(As a side note, I chose to use Astro components for anything server-only and Svelte for anything client-side. For my personal projects, I like Svelte’s approach of using a compiler to emit targeted DOM updates, as if I were using JQuery or vanilla JS.)
Both of these pieces of functionality are ones I could build myself, which I appreciate conceptually. Doing so in a framework-agnostic way, with Typescript, hot reload, etc. are what Astro brings to the table.
What I’ve built with Astro
Disclaimer: I haven’t used Astro professionally, though I would totally consider it if I worked at a startup where content-heavy microsites are needed with minimal fuss. However, I have thoroughly enjoyed using Astro for two of my personal projects, both focused around teaching.
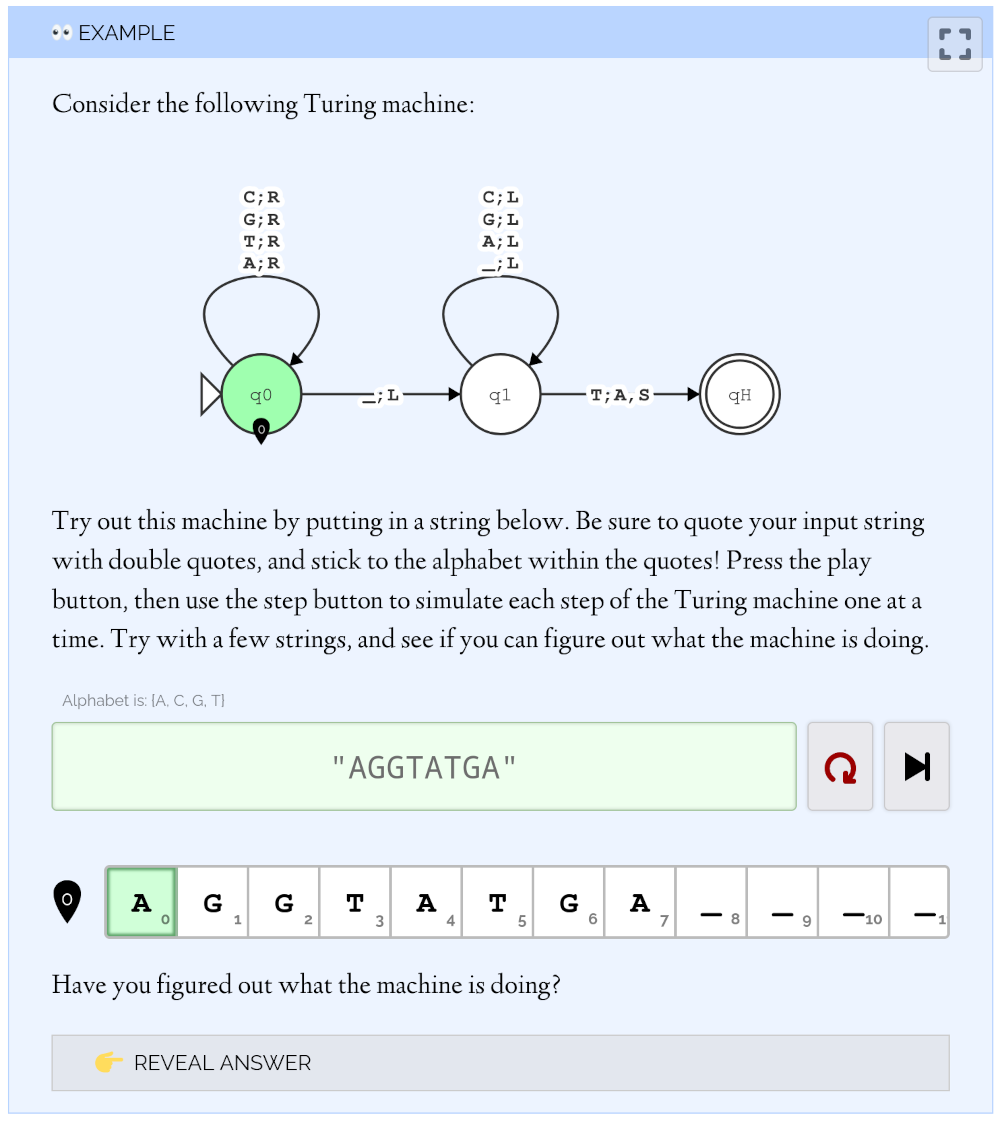
First, Interactive Computer Science, where I discovered Astro. I like using common server components for a consistent visual treatment across the website, for definitions and study tips for example. The client components are reserved for the interspersed interactive exercises and visualizations. I had a lot of fun building a full Turing machine simulator and its associated UX. Best of all, I was able to utilize the interactive exercises in my class!
I used this Turing machine simulator as an interactive exercise during my lectures
Second, NES development on the web. This is another content-heavy project, but the interactive visualizations are promiment. In particular, I was able to embed a Webassembly-based 6502 assembler and an NES emulator to allow writing 6502 assembly code and have it run right in the browser! Outside of this use case, I’m also using client components for the type of interactive visualizations I wish I had when learning Gameboy Advance programming before college, things like visualizing bit fields and other low-level data representations.
When learning about how graphics are represented on the NES, readers can change the top row and see the bottom rows update in realtime
As with any framework, I have spent time wrangling Astro. But overall, Astro, Typescript, SASS and Svelte are all tools that have allowed me to focus on the content of my visualizations, not the infrastructure that powers them.
Deployment/hosting
This part isn’t specific to Astro, but if you ensure your server-rendered HTML is static (no per-user differences, no fetching data dynamically for each request, etc.), you can deploy to any host that supports static HTML. For my pet projects, I’ve been happy using Fastmail’s static website feature. I could also have used Github pages of course.
Why not convert this blog to Astro?
It really feels like my blog is the perfect fit for Astro. To be honest, I think so too and I’m tempted to rewrite the entire blog using Astro instead of Jekyll. I can get rid of a bunch of hand-rolled Javascript and fully utilize a UI library like Preact as a first-class citizen (instead of just pulling it in via a CDN).
For now, however, I’m going to hold off, for the same reason I’m wary about all-in-one frameworks in general. The more dependencies there are, the more complicated both development and maintenance becomes. As a practical example, I have an item on my to-do list to upgrade the interactive CS website to the latest Astro, something that’s impeded on a conflict between the latest Typescript and the latest Astro. On the flip side, I feel like Jekyll, especially using it in conjunction with the default Github pages infrastructure, has been mostly set-and-forget. For my blog, I’m going to use “boring” technologies as much as possible. I want my blog to be cold-blooded software.
And if it weren’t for the sheer density of interactivity in my online teaching material, I would consider ditching Astro for those projects too. I’ve enjoyed Astro, but I wish I could use fewer dependencies.
]]>Avik DasContainerized services on a home server2023-08-23T00:00:00+00:002023-08-23T00:00:00+00:00https://avikdas.com/2023/08/23/containerized-services-on-a-home-serverWith my mini PC server set up with Debian, I prepared the server for actually running useful services. This time, I decided I would go all in with containers, hoping that will keep my applications self-contained enough that I don’t have to think about different applications stepping on each other.
I don’t claim to be an expert, and I’ve been piecing together this knowledge through many online resources. Like the last post, a lot of these are notes for myself.
One thing to note is I’m a very stubborn person, and a running theme is me doing things the non-standard way just on principle 😅
Podman and Podman Compose
The first controversial decision is to use Podman instead of the industry-standard Docker. Podman attracted me because it doesn’t use a daemon-based architecture, meaning individual containers will run under specific users, instead of a single daemon typically running as root. I could also say I was concerned about Docker’s approach to monetization, but Red Hat (makers of Podman) has generated some controversy lately as well. Mostly, I like the daemon-less architecture and thought this would be a good time to play around with some new technology.
Installing Podman, and the associated Podman Compose for small-scale container orchestration, is easy:
sudo apt install podman podman-compose
Note that prior to Bookworm, the previous stable version of Debian had some pretty old versions of Podman and required installing Podman Compose manually. Moreover, the old version of Podman meant you needed to install an older version of Compose from a branch. With Bookworm, I don’t have this problem.
Compatibility with Docker
With this setup, I can usually just use any docker-compose.yml file almost as-is. Instead of running sudo docker-compose -f <filename.yml> up, I just run podman-compose -f <filename.yml> up. Very convenient, thanks to the Open Container Initiative creating industry-wide standards that multiple tools can leverage. But there are two major differences I need to think about when adapting instructions for Docker to use Podman:
A lot of Docker Compose files use image names that are not prefixed with the hostname of any container registry. This is because Docker is configured to default to docker.io, the Docker company’s official registry. I can configure Podman to do the same, but I like being explicit with my code and configuration. This means if an image is referenced without a registry hostname, I just have to prepend docker.io/ to the name.
At least as of Podman Compose 1.0.3, I found .env file handling not where I was expecting it to be. Generally, there are two ways these files are used, either to substitute values into the Compose file itself and to pass along environment variables into the running containers. Using the env_file directive, you can use a filename other than .env. However, I found that doing so prevent values from being substituted directly in the Compose file. For now, I’m making sure each service I want to configure has its own directory containing a default-name .env file when needed.
Configuring inter-container networking
When trying to set up some more complex applications, I found that containers were not able to resolve each other by container name. In trying to fix this, I tried a bunch of solutions, only to find that I needed to reboot (or probably run some command, but rebooting did the trick). So, I don’t know everything below is necessary, and it’s worth trying just the first command to see if that’s enough. Just remember to reboot!
First, install the golang-github-containernetworking-plugin-dnsname package. Theoretically, this should be enough, as it allows containers to DNS resolve each other by container name, as long as they are in the same virtual network:
Another issue I encountered was errors around logging. This was especially relevant when I was trying to debug the inter-container networking issues I described above. I don’t know too much about this, but it seems like the standard journald-based logging requires some extra permissions. The way I ended up fixing the issues was to switch to file-based logging for the user in question (I talk more about the user setup below). For example, when setting up Immich, I updated the container config as follows:
sudo-u immich mkdir ~immich/.config/containers
sudo-u immich cp\
/usr/share/containers/containers.conf \
~immich/.config/containers/containers.conf # copy over the default config
sudoedit -u immich ~immich/.config/containers/containers.conf
Using Podman’s rootless architecture, I decided that I’ll run each service as a separate user. Additionally, I wanted these users to be system users. Unlike regular users, system users don’t, by default, have a login shell, so they can’t be logged into. They also don’t show in a listing of login users, say in the login screen of a graphical installation. This latter point is moot for me because I didn’t install a GUI. Again, I’m making these choices on principle.
First, I added a services group to make it easier to easily give common permissions to all the service users. By default, system users are placed in the nogroup group, so I wanted a shared group for these users.
sudo addgroup --system services
Next, I added the user. For example, when preparing to set up Forgejo, I created a system user called forgejo. Two things to note are that I have to explicitly ask the user to be added to the services group, and I have to explicitly specify the home directory. By default, system users have their home directory set to /nonexistent, which doesn’t exist and is not created by the adduser command. I was hoping to get away with no home directory, but unfortunately, Podman stores its data in the running user’s home directory.
sudo adduser \--system\--comment'Forgejo system user'\--home /home/forgejo \--ingroup services \
forgejo
# The above command should output the user ID of the new user. But if you# forget, you can check after the fact:id forgejo # in this case, the ID is 102
Next, I had set up subuids and subgids for the user. The way containers work is they run processes and create files/directories under “virtual users”. This way, the container-specific processes and data don’t clash with existing users on the system. To do this, subuids and subgids allow reserving a large range of user and group IDs for the parent user to allocate as needed.
# Check the current range of subuids/subgids# Format is "username:startid:numids"cat /etc/subuid
cat /etc/subgid
# Adjust the command to use the next available range# Format is "startid-endid"sudo usermod --add-subuids 1001000000-1001999999 forgejo
sudo usermod --add-subgids 1001000000-1001999999 forgejo
# Confirm the subuids/subgids were addedcat /etc/subuid
cat /etc/subgid
Finally, when running containers, I encountered errors related to the fact that the users running the containers were not logged in. The systemd login manager can start up a “user manager” for non-logged in users by enabling lingering:
# Use the user ID of the usersudo loginctl enable-linger 102
Note that the home directory, the subuids/subgids and lingering would automatically be set up for non-system users. But again, on principle, these users have to be system users!
Systemd
With this setup, I can already start up a service using Podman Compose. For example, for Forgejo, I would run:
# Run as the forgejo user# Run in daemon mode (in the background)sudo-u forgejo podman-compose -f /path/to/forgejo-compose.yml up -d
In fact, I would do exactly this to test out the service works. But, because Podman doesn’t use a global daemon, nothing exists to start up running containers after a system reboot (Docker supports this with the restart directive). Instead, I use systemd to manage the application as a service. I start by creating a service configuration file called forgejo.service. A few things to note about this service are:
It runs as the forgejo user, under the services group and with the home directory as the working directory.
All paths are absolute.
By setting the dependency via the After and Wants directives, I ensure the service starts up on its own after a reboot, and that too at the right point in the system initialization.
I can install this service by placing the configuration file in the system-wide services directory, enabling the service and starting it up.
# Running this in /path/to/forgejosudo cp forgejo.service /etc/systemd/system/forgejo.service
sudo systemctl enable forgejo.service
sudo systemctl start forgejo.service
echo$?# Confirm the service started up correctly# The return code should be 0
At this point, the service will start up automatically after a reboot. If I want to stop or restart the service myself, I can do that too:
Finally, the start and restart commands are a bit of a black box, and you don’t get to see errors or other logs on the command line. Instead, you can use journald to view the logs. Unfortunately, this doesn’t include all the logging, namely the part where the container images are downloaded. Given that this part can take a long time, I suggest running podman-compose manually to download the images before running it via systemd.
sudo journalctl -fxeu forgejo.service
All of this might seem like a disadvantage compared to Docker, but I prefer this system. I think it follows the Unix philosophy, letting Podman focus on containerization and systemd focus on service lifecycle.
Reverse proxy
There has been a lot of setup, but we’re almost done. The last part is making the service available on the internet, so I can access it when I’m not at home. I could definitely use a self-hosted VPN, and I might do that for some services in the future, but I want to share some of these services with other people.
The basic setup has a few parts:
I own some domains, so I use a subdomain for each service pointing to my home IP address.
My router is set up to forward specific ports to my server.
On the server, the Caddy web server redirects to different internal ports based on the subdomain being accessed.
Here’s the final architecture, which I’ll describe in more detail below:
Subdomains point to my home IP address
This part is pretty straightforward. I just log into my domain registrar’s DNS settings and create a new subdomain, set up as an A record. Generally my IP address doesn’t change frequently, but it is technically dynamic, so I want to automatically update the A record when my IP address changes. To do this, I use DDclient.
The exact details of how to set up DDclient will depend on your DNS provider, but you should get a configuration dialog during installation or if you manually reconfigure:
sudo apt install ddclient
# To reconfigure latersudo dpkg-reconfigure ddclient
# Or manually edit the configuration file
sudoedit /etc/ddclient.conf
# Don't forget to manually refreshsudo ddclient
What I like to do is set up my subdomain to point to 0.0.0.0, update the configuration to include the new subdomain and refresh. This way, I can verify the subdomain is going to update correctly if my IP address changes.
Using Caddy as a reverse proxy
I want all the services on my server to be available over port 443, instead of having to specify the port when accessing most of the services. Additionally, I don’t want to have individual containers bind to ports like 443, which would require the service users have additional privileges. The way to do this requires a few steps:
Configure my router to forward ports 80 and 443 to my server.
Use Caddy with virtual domains as a reverse proxy to the services. Caddy is the only service on the system listening on ports 80 and 443. I like Caddy for this simple use case because, unlike Nginx, the configuration is simple and I don’t have to separately configure Certbot to provision Let’s Encrypt HTTPS certificates.
Ensure that services that expose ports only expose non-privileged ports, ones greater than 1024. For example, internally, a service might bind to port 80 inside the container but expose that to 3000. This is something I have to check in the Podman Compose configuration files, because a lot of times, they try to expose privileged ports. I also make sure to not enable HTTPS for that service if that’s an option.
After configuring my router’s port forwarding and starting up a service on a non-privileged port, I installed Caddy:
sudo apt install caddy
Before configuring any specific services, I need to add some global configuration. Opening up /etc/caddy/Caddyfile, I commented out the default configuration and added the following:
{
# Used primarily as the email to associate with Let's Encrypt certificates,
# in case any communications are needed.
email my_email@example.com
}
Now, I can add service-specific configuration, one block per service. Almost all the services are similar:
mysubdomain.mydomain.com {
# Point to whatever port the internal service exposes
reverse_proxy :3000
}
By default, since I don’t specify a protocol (for example http://), Caddy defaults to HTTPS and provisions a Let’s Encrypt certificate for this domain. This works automatically as long as port 80 on my router is being forwarded to this Caddy instance.
Now, I just restart Caddy and I’m good to go:
sudo systemctl restart caddy
Note that many services allow you to specify what hostname they will run on. This is typically configured as an environment variable or as part of a configuration file. Among other reasons, configuring the hostname is useful for display purposes within the application.
The clone URL displayed for my git repos on my Forgejo instance shows the correct domain due to application-specific configuration
Tooling for managing services
Because I have to customize my application installations with details such as file paths, expose ports and user information, I created some tooling to manage these installations. The tooling is straightforward:
Each service’s configuration is stored in its own directory. The directory typically consists of the Podman Compose file, the systemd service file and optionally, a .env file.
The parent directory for these services contains a script to copy over the systemd service file to the right place and a README with useful commands. All of this serves as a reminder for myself how to install and manage these services.
These files are managed using git and stored on my Forgejo instance. Meta!
I’m not sharing the repo because I don’t want to share all the specific details of my server setup, like file paths and hostnames.
With these steps, I’m happy with how isolated each service is, how it automatically starts up with the machine and how little extra maintenance is needed once I get a service running. Even getting the service installed in the first place is easy thanks to containerization. I installed two services recently in just a few minutes.
Nothing about these steps are revolutionary, as they use off-the-shelf tools combined together exactly as they are meant to be. Having this documented here hopefully helps others understand the larger ecosystem of tools and how they can be put together to spin up a useful, low-maintenance home server.
]]>Avik DasSetting up a micro PC as a Linux server2023-08-21T00:00:00+00:002023-08-21T00:00:00+00:00https://avikdas.com/2023/08/21/setting-up-a-micro-pc-as-a-linux-server
My little server, sitting next to my router
This blog started at the end of 2018 as a way to document how I set up my Raspberry Pi. Some time ago, the Pi finally broke down, and I’ve had terrible luck with Micro SD card corruption. After a few unsuccessful attempts to get the Pi running again, I picked up a used Dell OptiPlex 7040 Micro. Here are my notes on getting this server set up, since I’ve learned a thing or two in the last 4.5 years. Most are notes for myself.
Today’s post will cover getting the server hardware set up and Linux installed. I’ll cover more about the home server capabilities in later posts.
Hardware
As mentioned above, I’m using a Dell OptiPlex 7040 Micro because that’s what I found on Craigslist. Given that I was happy with a Raspberry Pi 3B+ in the past, this system is overkill. But, it is nice having a modular, upgradeable system compared to a System on a Chip (SoC).
To that point, I picked up a 1TB 2.5” SATA SSD to swap into the system, and I installed an older 512GB M.2 NVMe SSD I had lying around (it was one I thought had died, so I had replaced it on a different machine, but it turned out to be working fine). I’m using the NVMe drive for the OS installation and /home partition, and the SATA drive for the actual storage. For example, I installed Immich to back up my photos, and I’m using the SATA drive for storing the photos.
It’s nice to have these types of hardware slots inside the small form factor, compared to using a USB drive sticking out of my Raspberry Pi.
Networking
The Dell OptiPlex 7040 does support wireless, namely WiFi and Bluetooth, but the unit I picked up didn’t have the necessary hardware installed. I did some research on installing an M.2 wireless module. Ultimately, it’s not that important to me because I placed the machine near my router with an ethernet connection, so I passed on adding this hardware.
Installing Debian
Having started my Linux journey with Ubuntu, I now run Debian on my personal laptop. I went with Debian for the server as well. The newest stable release, Bookworm, recently came out, so I’m okay with stable for now and will update to testing if I feel anything has gotten too old.
I didn’t install a graphical desktop environment because I wanted the machine to be a headless server. I configured an SSH server during installation, so I can remotely log into my server. Just as importantly, I didn’t configure a web server. Debian’s default is to use Apache, and I prefer to use Caddy or Nginx for my relatively meager needs.
Overall, installing Debian with the graphical installer was straightforward, but there were a few additional things I needed to do.
Configuring EFI
It seems there’s a bug with the EFI firmware on the OptiPlex specifically related to the NVMe drives (everything worked out of the box when I initially installed Debian on the original SATA drive). Basically, Debian puts its EFI binary in /boot/efi/EFI/debian/grubx64.efi. Even after going into the boot settings on the machine and changing the EFI binary path, the machine seemed to be looking in a default location of /boot/efi/EFI/boot/bootx64.efi, causing the machine to think there was no installed OS.
Fixing that was simple once I figured out the issue, with the following steps.
Start up the Debian graphic installer and open a terminal session. When prompted, mount /dev/nvme0n1p1 as that’s the boot partition. Then, copy over the EFI binary from the original location to where the machine expects it:
cd /boot/efi/EFI
mkdir boot
cp debian/grubx64.efi boot/bootx64.efi
Reboot, and Grub should start right up.
Configuring sudo access
I didn’t want to keep switching to a root user for all my administration, so I set up sudo:
Also, adding export EDITOR=vim to my .bashrc ensured that sudoedit (to edit files as root without running your editor as root) uses Vim.
As I’ll talk about in a later post, I will mostly use containers to run software. But historically I’ve used asdf and some plugins for node.js, Ruby and Python. I installed those too, probably out of habit.
Configuring the storage drive
When I install Debian, I always separate the /home partition. If I do this during a new install, then the installer can set up the system to automatically mount the right partition as my /home directory. If I want to preserve an existing /home partition, I’d have to set up the auto-mounting myself.
Either way, I also wanted to auto-mount the SATA storage drive. First, I had to decide which file system to use for the storage drive, and I went with Ext4 for simplicity. I would have enjoyed trying ZFS, but without native support in Linux (that I could find), I stuck with whatever was well supported:
sudo fdisk -l# find the device for the drivesudo mkfs -t ext4 /dev/sda1 # format that device
Now to automount the drive (and these steps generally apply for a /home partition as well):
sudo mkdir /mnt/storage # create the mount pointsudo blkid # figure out the UUID of the drive
sudoedit /etc/fstab # see below for what to addsudo systemctl daemon-reload # pick up changes to /etc/fstabsudo mount -a# mount!
When editing /etc/fstab, add the following line:
# UUID is based on the output of blkid
# dump=0 - I'm not sure what exactly this does
# pass=2 - `man fstab` says use "2" for non-root filesystems
UUID=... /mnt/storageext402
EDIT (Sep 5, 2023): I got a suggestion about an alternate way to identify disks in /etc/fstab, which took me down a rabbit hole. Here’s what I found:
Firstly, this was something I already knew, but you don’t want to use device identifiers like /dev/sda1. There’s no guarantee these will stay the same across boots. That’s why I used the UUID. The UUID is stable, at least until reformatting.
The suggestion was to use the paths inside of /dev/disk/by-id. These are symlinks to files like /dev/sda1, but the filenames are human readable. For example, instead of a UUID like I’m using, my SATA SSD partion would be named ata-INTEL_SSDSC2KB960G8_BTYF92160AB7960CGN-part1. Definitely nicer! This seems like the way to go, and I’ll try it out in the future.
As always, the Arch wiki is fantastic, even for non-Arch users. Note that this wiki page doesn’t talk about the approach mentioned above, but the forums sure discuss it at length!
With all these changes above, I now have a running Debian server that I can start playing around with. Next up is how I installed the right software to make the server useful!
]]>Avik DasMy two semesters of teaching2023-07-17T00:00:00+00:002023-07-17T00:00:00+00:00https://avikdas.com/2023/07/17/my-two-semesters-of-teachingIn 2022, I got the opportunity to live out my dream of teaching a university course, and that too in theoretical computer science. Despite how busy my day job was, I knew I had to take that opportunity or I would regret it. After teaching for two semesters, I found the experience both exhilarating and too much of a time commitment to continue next semester. To get into the habit of writing again, I want to reflect on that experience.
Disclaimer: these are my thoughts after just two semesters of teaching, and I don’t mean for this to be any sort of “words of wisdom”. For that reason, I’ll keep my thoughts light. If anyone with more experience wants to weigh in, I would love to hear your thoughts!
There’s a lot of trial-and-error. I thought teaching required credentials and apprenticeship, the way I saw student teachers practice teaching in high school. Instead, I was given pretty much free reign to teach how I wanted, as long as I submitted grades at the end of the semester. I found it simultaneously freeing to have that autonomy and scary to be trusted to that degree. But, even if I had the credentials, I would still need to adapt my teaching style every semester based on some (informed) trial-and-error. I want to give a huge thanks to my mentor at the same university who guided me on the course design.
Going the extra mile is really expensive. Students appreciated my timely grading, detailed feedback and copious office hours throughout the semester. I wanted students to have as many resources as possible. For example, homework assignments were due as late as possible on the Tuesday before a Thursday exam, and I tried to finish grading by midday on Wednesday so students could use that feedback to study for the exam. Unfortunately, doing this takes a lot of effort, and probably is the primary source of me burning out on teaching. I don’t blame teachers who prioritize ease of instruction over individualized support.
It’s hard to teach within a broken system. And by system, I mean all of education, not the institution. Students often take a full course load while working full-time due to financial constraints, something I never had to do because of my privilege. They also were not always prepared thoroughly by previous classes, again something I was privileged enough to not worry about because my parents could afford the rent needed to send me to well-funded schools and I had the time to focus on my academics even before college. No matter how much effort I put into teaching, I can’t help someone who doesn’t have the 10-12 hours a week needed to truly learn the material.
Inclusive policies can help decrease the burden. Recordings for all lectures and office hours, open book exams, flexible deadlines if someone asked… all of these prevented the need for additional scrutiny on my part to determine if someone was “worthy” of an accommodation. Sure, if someone had medical documentation, they could request such accommodations via the university, but inclusive policies benefit those who can’t get a formal diagnosis or are afraid of retaliation. If I kept teaching, I would continue finding ways to extend “accommodations” to all students by default, both to make my life easier and because these accommodations are, as the Speech Prof says, just good teaching practices.
I once heard that the first year of teaching is just learning to keep your head above water, and I had to give up before I got into the groove, apparently. That does mean the above reflections are based on very little experience. But to be clear: I loved teaching, and I intend to find my way back to it.
]]>Avik Das“It’s not peaches and cream either for men”2021-11-29T00:00:00+00:002021-11-29T00:00:00+00:00https://avikdas.com/2021/11/29/its-not-peaches-and-cream-either-for-menI spend a lot of time talking about men’s mental health because it’s what I, as a man, know about. And like with everything, the truth is complicated. We live in a patriarchal society that privileges men in certain ways, but also hurts them in other ways. The harmful effects on our heavily gendered society especially show themselves when racial or class oppression enter the picture. But ultimately, I have to listen to the experiences of others to piece together this complicated web of good and bad. So, when I came across Crossing the Divide, four accounts of transgender men who have experienced life being treated as women and now living as men, I was fascinated.
You should read the article to see how gender in our society isn’t clear cut. But, I do want to expand on some areas where we can support men better.
(The title of this post is a quote from Trystan Cotten in the article.)
Racial barriers
One of the contributors, Trystan Cotten talks about how being African America affected his life experiences pre- and post-transition. Cotten says it beautifully: “Life doesn’t get easier as an African American male. The way that police officers deal with me, the way that racism undermines my ability to feel safe in the world, affects my mobility, affects where I go.” This lack of safety is gendered too, as he mentions how he did not get pulled over or was let off pre-transition, but post-transition, his increased interactions with the police start with him being asked if he has any weapons.
Alex Poon talked about his genetics as a Chinese man not setting him up to have a “lumberjack-style” beard, underlying a fear that his stereotypically feminine facial features will impede his masculine presentation.
Both these stories make it clear why racial equality is needed. Whether it’s Black Lives Matter, or representation of Asian men in media, gender equality can’t be achieved without racial equality. Regardless of your gender identity or your race, if you want to create a society that supports men, support racial justice reform in all its forms.
Support systems
Cotten also points out how there aren’t spaces for men to share their mental struggles. Contrasting his experience in gay, feminist and women’s circles, “there was a space and place you could talk about your feelings. In the last, you know, 10 years or so [post-transition] I can’t find those spaces necessarily for men, and I don’t know if men necessarily make those spaces for each other.”
And it’s not just a responsibility for those of us who are struggling, because we can’t share if no one is listening. Both of the other contributors, Zander Keig and Chris Edwards, talk about how society became less friendly toward them once they transitioned. Keig sums it up well: “What continues to strike me is the significant reduction in friendliness and kindness now extended to me in public spaces. It now feels as though I am on my own: No one, outside of family and close friends, is paying any attention to my well-being.”
Once again, we can create a better society for all by creating safe and inclusive environments for men:
Some of that is on men who are already creating communities, for example by adopting the right community rules to ban toxicity and allowing (respectful) discussion of topics like mental health. Often, communities for men are taken over by trolls shifting the conversation to blaming women, instead of focusing on the problems men face in an overly gendered society. Community builders need to keep the conversation on a productive discussion of men’s issues.
Some of the responsibility falls on everyone who is trying to create social safety nets. As Keig points out from his experience in social work, “when I would suggest that patient behavioral issues like anger or violence may be a symptom of trauma or depression, it would often get dismissed or outright challenged. The overarching theme was ‘men are violent’ and there was ‘no excuse’ for their actions.” Men who behave violently do need to be held accountable for their actions, but we also need to provide better mental health services that understand how those men end up acting violently in the first place.
The stories make it clear there are societal advantages for men, so I don’t want to suggest women have “made it” in our society. But for many men, especially but not limited to those in marginalized groups, the picture isn’t rosy. We need to create a society that treats everyone as valuable, regardless of other factors like race. We need to create support systems to elevate all those in need, at times taking into account the specific needs men have. Only then can we create a society that supports men.
For what it’s worth, I raise awareness for a men’s health charity called Movember because mental health is really important to me, and men experience mental health struggles in a specific way that’s deep rooted in our culture of tough masculinity. If you want to help, please reach out to a friend, participate in a Movember event to keep the conversations going, or donate to Movember. Let’s save some lives!
]]>Avik DasIt’s okay to not be okay2021-11-02T00:00:00+00:002021-11-02T00:00:00+00:00https://avikdas.com/2021/11/02/its-okay-to-not-be-okayWhat I’m about to say applies to everybody, but with Movember and my own experience as a man in mind, I hope my words will at least be useful to the men who read this. It’s okay to not be okay.
The last year and a half have been damaging to all of us. Losing a job makes us feel like less of a provider, and the pandemic has been profoundly isolating. Worse still, for some of us, this isolation has not even been anomalous. Exaggerated maybe, but not anomalous. And I’m sure for many of us, there has been a time in our lives where we latched onto ideologies that ultimately hurt us as we looked for connection. The polarization and echo chambers enabled by social media have made this self-destructive behavior easier than ever.
I’m here to say from personal experience, it’s okay to not be okay. Your need for meaningful connection and personal autonomy is valid. Feeling overwhelmed is valid. Feeling like you’re drowning in the expectations of others is valid. Feeling like things are not going your way is valid. Feeling like no one gives you the attention you need is valid. We don’t have to tough it out. Asking for help and being vulnerable won’t make you less of a man.
That’s it. No solutions right now, no advice on what to do next. Just acknowledgement that your feelings are valid.
I raise awareness for Movember because mental health is really important to me, and men experience mental health struggles in a specific way that’s deep rooted in our culture of tough masculinity. If you want to help, reach out to a friend, participate in a Movember event to keep the conversations going, or donate to Movember. Let’s save some lives!
]]>Avik DasSpace curves and twist2020-12-29T00:00:00+00:002020-12-29T00:00:00+00:00https://avikdas.com/2020/12/29/space-curves-and-twistI ended my last post about rendering curves in 3D with an example of a curve whose cross-sections end up mismatched at the ends. This is despite the fact that the curve uses the Rotation Minimizing Frame to define the cross-sections, meaning we don’t expect the curve to twist around. I went ahead and implemented a rendering of that curve to show what I mean:
A non-planar curve might end up with misaligned ends
If you consider a curve that’s planar, meaning it lies completely within a flat plane, that curve will never have this problem. Imagine walking on the “top” side of the cross-section. You’ll always be able to stay upright from start to end. Only when you move out of the plane would you end up pointing in a different direction along the way, and therefore in a different direction when you come back to your starting point.
What gives?
Compensating for the mismatch with twist
I don’t have a deep philosophical reason for why this mismatch sometimes happens on non-planar curves. But when it does happen, it means the Rotation Minimizing Frame wasn’t the best way to render that closed curve. Instead, we should have had the cross-section twist around so that by the time the curve closed in on itself, the starting and ending cross-sections line up.
We don’t want to apply this twist sharply at one point, so we can apply it incrementally across the entire length of the curve:
By spreading out the $180^{\circ}$ mismatch over the entire curve, the cross-sections line up
So how do we determine that $180^{\circ}$ is the right amount of mismatch to compensate for? Simply compute the Rotation Minimizing Frames at the start and end (which will require computing the frames in the middle), then compare the orientation of the two frames. Because the first and last frame should overlap, you can just compute the angle between the reference vectors $\hat{r}$ of the two frames.
After coming back to the starting point, the final frame may be rotated compared to the initial one. The angle between the same vector on the two frames is the overall end-to-end twist.
Because the initial reference vector $\hat{r_0}$ and the final one $\hat{r_n}$ are on the same place, you can find the angle between them using the dot product between them (remembering that the vectors are unit vectors with length $1$):
Here, $\theta$ is the end-to-end twist we were looking for. We can just linearly interpolate this overall twist across the rendered frames, rotating each frame a fraction of the full twist until the entire twist is accounted for.
Added twist
In the same way that the compensating twist for a mismatch can be interpolated along the curve, so can any additional twist. In particular, adding a multiple of $360^\circ$ on top of any compensating twist will still leave you with matching ends. You can see that with any of the curves in the visualization below:
What’s really interesting about these curves is that they are all “equivalent”, at least under certain transformations I’ll talk about more in the next post.
Accumulating twist
One thing you may have noticed from the twist calculation above is that the range of $\arccos$ is between $-180^\circ$ and $180^\circ$. That makes sense, in that two vectors can only be up to $180^\circ$ apart on the same plane. However, if you start with a small twist and transform the curve gradually, you may end up accumulating twist along the way.
The easiest way to see this is by “unfolding” a figure-8 loop, which you can see in the interactive demo below:
We start with a pretty normal figure-8, though one of the arms has been offset a bit to show how the unfolding will proceed. Over time, the curve flattens itself out into a circle, but notice what happened to the rotation of the frames along the circle. In order to preserve the relative orientation of the frames along the curve, the unfolding accumulated $360^\circ$ of twist!
A planar circle can be rendered without any end-to-end twist, just like any planar curve. But what the demo hints at is that a figure-8 with no twist and a planar circle with no twist are not equivalent! At least not equivalent under the unfolding transformation that we did. Instead, a figure-8 with no twist is equivalent to a planar circle with $360^\circ$ of twist.
This process of accumulating twist over the course of a transformation plays a big part in my research, something I’ll cover in more detail in the next post.
The idea of a curve twisting is central to my undergraduate research. Non-planar curves can end up with mismatched ends when rendered using Rotation Minimizing Frames, and when that happens, compensating twist has to be added to the curve. Curves can also have some amount of additional twist, which can be applied the same way as the compensating twist.
With the concept of twist established, the next post will talk about how a curve’s twist is somehow intrinsic to the curve, and only changes in very specific ways when the curve is transformed.
]]>Avik DasVulnerability, leadership and paternity leave ft. Erran Berger2020-11-16T00:00:00+00:002020-11-16T00:00:00+00:00https://avikdas.com/2020/11/16/vulnerability-leadership-and-paternity-leave-ft-erran-berger
Since I started writing, I made a point to have important conversations with the people in my life and share those conversations with a wider audience. During Movember, I try to have deep conversations about men’s health. Last year, I talked with a mentor of mine, Nash, and this year, I talked with Erran Berger, VP of engineering for the Consumer Experience org I’m a part of at LinkedIn.
At LinkedIn, one of our core values is open, honest and constructive dialogue, and a culture like that depends on the initiative and support of leaders. Erran has consistently demonstrated that value. During the COVID-19 pandemic, he opened up to the entire Consumer Engineering org as he shared what was top of mind for him both professionally and personally. For that reason, I’m honored to have spoken to him about the expectations put on men and how we can bring about gender equality.
Before starting our conversation, Erran asked me where my passion for talking about men’s health came from. It’s important for me to share that, as it provides some context for our conversation:
Avik: The mental health aspect of Movember is really important to me. I have, in the past, felt discouraged from talking freely about my feelings. LinkedIn, especially this last year, has encouraged everyone to talk more freely, but in general, there’s the idea of men needing to be tough and not showing emotion. I wish I had more close interactions with other men, but sometimes, when I expressed frustration, I’ve heard, “that’s just how it is.” Movember is a movement that encourages us to engage in meaningful dialogue. More than just me, other people are doing the same thing this month, and that encourages me further.
Secondly, as an example of the compassion Erran demonstrates, he prefaced our conversation with an important point about privilege. It’s possible to simultaneously talk about the issues we face as men while contextualizing those issues with the privilege we have:
Erran: As a white male, I could not be more in a position of privilege. I’m trying to be mindful to not have this interview come off as not acknowledging that privilege.
Avik: What does masculinity mean to you?
Erran: So there’s what is the textbook definition of masculinity, but it’s not necessarily one I want to embody. There’s a disconnect between my definition and the dictionary definition. The dictionary definition of masculinity is “Qualities and attributes regarded as characteristics of men” and that is problematic for me because it re-enforces an outdated notion of gender roles. Gender roles have, for far too long and still today, been defined by really outdated expectations of what a man should do and what a woman should do, what men and women are good at. It’s ridiculous. There is no singular definition of what a male’s role in society is, it varies from person to person, from relationship to relationship, from society to society.
And so, for me personally, masculinity means being a good partner to my partner (who happens to be female), a good parent to my kids, splitting and sharing all responsibilities in our household equally with my partner, and trying to be as open and vulnerable with my thoughts, feelings and emotions as I can be.
Avik: This goes right into the other topic I want to talk about: expectations. Having a rigid definition means there are rigid expectations, but what you talked about is, there are characteristics you prefer and it’s all about what you make out of it.
Erran: Yes. And for me, it’s problematic that those [expectations] are influenced by centuries of gender discrimination and inequity.
Avik: You are a leader in a large organization. Have you ever conflicted with the expectations put on you as a leader? How have you found your own leadership style?
Erran: In general, there are traits associated with leadership, like being a strong voice in the room or projecting executive presence. These traits are problematic because they are exclusionary of all sorts of people who can be fantastic leaders. As an example, people connote the term “inspiring”—which is important as a leader—with someone who is super charismatic and can get in front of the room to charm an audience. But certainly, that’s not the only way to be inspiring as a leader. Quiet leadership can be inspiring as well. Introverted leaders can be super inspiring and successful.
Specifically for myself, I put a high premium on vulnerability as a leader. Being genuine and vulnerable helps you connect with people in a way where people will want to follow you. It’s a trait that’s valuable as a leader, but many people may not naturally think it’s something a leader should be because they think it shows weakness and it violates the stereotype of the unflappable, stolid leader.
But being vulnerable doesn’t actually show weakness,it’s quite the opposite. At the end of the day, your relationship with your team and the people you are leading—the trust with them—is foundational above anything else. It’s much easier to build trust when people can relate to you and know you’re being honest with them. Vulnerability and openness is very helpful to build that type of relationship. Then everything else can follow, like inspiration and vision, if you have trust.
Avik: You mentioned this idea of connecting with other people and that being an important part of being a leader. Who in your life do you feel comfortable opening up with?
Erran: Family, first and foremost: my immediate family, my brother and sister-in-law, and my extended family. Then my friends. I have a really close group of friends, many of them men, but not only. If I’m having a tough time, with a personal or professional issue, I can go to them, and I know I won’t be judged but will be treated compassionately with support.
Relationships are bi-directional. The relationships I described are ones I’ve invested in for decades. In order to get to that depth of understanding, compassion and support, that’s not something you get within a short amount of time. Different people have different thresholds to engaging in those conversations, in terms of comfort and trust. I trust people pretty quickly, I feel comfortable and vulnerable pretty quickly, but every relationship takes time.
Avik: You’re right about relationships being bi-directional. What are some of the things you have done, and other people have done, to foster that level of closeness?
Erran: I don’t think there’s any substitute for just spending time together. Especially now [during the pandemic], it’s hard forming and building on relationships when you can’t see each other face-to-face. It’s actually really hard. I don’t know what the science says, but spending time in person versus doing it virtually, being able to hug and touch and laugh in close proximity without a mask, seeing their face… somehow there’s an emotional and a psychological element I think is really lacking right now.
Time spent, being vulnerable to each other, talking about difficult subjects, being emotional, these are all things that build layers and layers over time with every successive difficult conversation.
Avik: This is great, because it tells people this time [in the pandemic] is tough and it’s not your fault. This is just the world right now.
Erran: In fact, it requires we all work harder on these relationships, because we have to make up for the lack of in-person communication, the serendipitous moments that happen when you’re just hanging out with friends or family.
Avik: The last thing I want to ask about is: you recently went on paternity leave. Why was that important to you, and should companies invest in paternity leave?
Erran: I’m glad we’re talking about it. This gets to the core of the problem with [the textbook definition of] masculinity in society and how it manifests itself. When I have a baby, I cannot nurse my child, I cannot breastfeed my child, I cannot give birth to a child. But quite literally everything else that comes with raising a child, I can do. Yet, there is a fundamental meme in society—about what the role is of a man versus a woman—that assumes a bunch of stuff from the day you come home from the hospital with the baby.
The consequence of that is women’s careers are affected when they have children and take time off. There’s a lot of data to support the negative impacts [having a child] has on women’s careers, and it’s hugely problematic. It’s important we acknowledge that men can play a very active role in the raising of our children from the day they are born. It’s incredibly important to our families that we do so, that we have open conversations with our partners about how responsibilities will be shared.
And the only way I can truly play an active role is if I’m at home when the most is required, which is when there’s an infant at home. So when I frame it that way I felt like I had no other choice than to be at home. That’s why I took so much time off and I would encourage any other male employee of LinkedIn to do the same thing that I did.
Avik: As you pointed out, this idea of men not taking a role in their parenting is an example of clearly defined gender roles, and it’s something we need to change. I’m very grateful you set that example for the organization, and of course, because we work at a company that sets that example as well.
Erran: Men taking longer [paternity leaves is] one way we can start to break down gender roles and how we can bring about gender equality across the board, both in society and in the workplace. It’s by men leaning much deeper into behaviors and responsibilities that have been traditionally associated with women. It’s good for us as men, and it fixes some things that are fundamentally broken about our society.
I found this dialogue very insightful. Some of the key takeaways for me were:
Masculinity is what you make of it. You don’t have to adhere to the textbook definition where it’s problematic, or where it hurts you. Most importantly, masculinity is positive if you make it positive.
Vulnerability is an important trait for leaders, and really for everyone, as it builds more meaningful connections with others.
Relationships take time to develop. There is no substitute for time spent together, having honest and open conversations. This is especially hard now during the pandemic, when connecting in person is often not an option, so we need to work harder to establish these relationships now.
Men need to take an active role in raising their children, regardless of what traditional gender roles prescribe. This is the way we can break down those gender roles, benefiting us men and our future generations.
]]>Avik DasWhy men’s health depends on feminism2020-11-01T00:00:00+00:002020-11-01T00:00:00+00:00https://avikdas.com/2020/11/01/why-mens-health-depends-on-feminismToday marks the start of Movember, a month-long fundraising effort focusing on men’s health. For me, I participate to bring awareness to mental health issues, specifically the way men struggle to handle their mental health issues.
The central problem with our struggle with mental health is a lack of support, which comes from two sources that feed into each other. First, we don’t talk about our emotions nearly enough, and we don’t build a support network to talk to in the first place. Men, how often have you felt isolated at a time of emotional need? If we’re going to solve these issues, we need to look to a movement that has forged a path for us: feminism.
Feminism works to tear down a system that hurts men as well. Photo by chloe s. on Unsplash
Isn’t feminism about women?
While feminism looks at societal problems through the perspective of women’s experiences, the core of the movement is to tear down a patriarchal system that affects people of all genders. Key among this framing is the idea that people don’t have to stick to stereotypical expressions of their gender identity, and in fact, some expressions aren’t even inherent to those gender identities.
When it comes to masculinity, it’s okay to identify as man and even to take on traits we associate with manhood. However, it harms us to adopt the negative norms associated with that identity. These negative norms, and the negative ones alone, form what is known as toxic masculinity.
A prominent example of such a negative association is the idea of a “tough” man. Bottling up your emotions is considered a male trait. But as men, we should be open about our emotional state. Doing so early helps us process those emotions, get help responding to those emotions and avoid building up those emotions to a point where they are too strong to manage. This requires two parties: we as men have to open up, and we have to encourage other men to open up without judgement.
By being open, it helps us avoid harming ourselves, but also helps us avoid harming others, including women. And for that reason, removing the negative parts of stereotypical male expression is a topic feminism has explored, the lessons from which we can build upon.
Intersectionality
Feminism has, at times, struggled with intersectionality, the idea that marginalization compounds itself when multiple types of discrimination are involved. Whether it’s an issue of white feminists excluding People of Color, or cis-gendered feminists excluding trans women, no movement of social progress can survive without acknowledging the diverse ways people experience the world.
Factors such as race add another set of expectations on people, including men. Photo by Clay Banks on Unsplash
In the same way, the police brutalization of Black men and a culture of “othering” Black communities leads to an expectation of Black men to be hypermasculine in all the wrong ways. Socioeconomic oppression causes men in poverty to cling onto traditional notions of masculinity that give them a tiny bit of power over others. These toxic expectations come from different sources, whether that be racism, classism or other aspects of the matrix of domination (another term originating from intersectional feminist thought). The important part is all these interconnected phenomena matter when separating our male identity from the societal factors that prevent us from opening up.
Putting this all together, when we as men strive to move forward in the world, we need to re-evaluate the expectations put on us. In the workforce, my goal is to become a leader within my team and company, but I don’t have to do so with aggression and putting down others. I can do so with empathy. Flipping these expectations means I don’t have to live up to a standard I’m not comfortable with, which is good for my mental health, but it also means others can grow in the ways they feel comfortable.
This month, join me in my journey to be more vulnerable, and in convincing other men to open up as well. Along the way, we can look to the progress feminism has made for guidance.
The Movember Foundation advocates for men’s health by bringing awareness and funding social programs. If you want to be a part of this movement, please consider donating to my Movember page. And please spread the word, so we can take action together.
]]>Avik DasRendering curves in 3D2020-09-08T00:00:00+00:002020-09-08T00:00:00+00:00https://avikdas.com/2020/09/08/rendering-curves-in-3dThe reason I wrote my lasttwo posts on WebGL is because I want to write about my undergraduate research from my time at college. My original paper was written with a bunch of messy C++ code, and I want to do two things:
Make the concepts behind my research more accessible.
Make the results from my research available to people without needing to compile and install additional software. That means WebGL!
Today, I’ll start with some background material: curves and moving frames. While you don’t need to install new software to play with the demos, you will at least need a sufficiently new browser that supports WebGL and modern Javascript features (like modules).
Properties of curves
When you describe a curve in any number of dimensions, there are two important properties involved:
The tangent vector at a given point, describing where the curve is headed from that point.
The normal vector at a given point, perpendicular to the tangent. In certain cases, which I’ll talk about more below, the normal describes where the tangent is headed from that point.
Intuitively, the tangent points along the curve, and the normal points away from it.
If you’re familiar with calculus, you may notice I’m describe rates of change, meaning derivatives. Indeed, based on the above definitions, the tangent is simply the derivative of the curve with respect to position and the normal is the derivative of the tangent! This also means, if we have a bunch of discrete points that define a curve, we can approximate these derivatives using finite differences:
(All of this is subtly wrong, but I’ll talk later about what’s wrong and how to fix it.)
Take the surrounding points, find their difference, then divide by the distance between the points. The closer the discrete points, the better the approximation. The same goes for the normal, but this time calculating the differences between the surrounding tangents.
Because these two vectors are rates of change, they have magnitude describing how fast the curve or the tangent are changing. For our purposes, however, we only care about the direction of the change. But, the magnitude of the normal will give us some insight, so in the following interactive demo, I’ve plotted:
The fixed-size tangent vector.
The “actual” normal vector (scaled so it’s visible).
The fixed-size normal vector.
You’ll notice that the approximation gets better—the tangent and normal point in the directions you intuitively expect—with more samples along the curve. This is because the step size, the $h$ in the above formulas, gets smaller.
The other very important observation is how the normal behaves around the middle of the curve. In the middle is the inflection point, the point where the curve switches from curving in one direction to curving in the other direction. At that point, the curve approximates a straight line, meaning the tangent is not changing direction and the normal is essentially the zero vector.
This also means the normal points down on one side of the inflection point, getting smaller and smaller until it starts getting bigger on the other side. The unit-length normal vector suddenly switches directions, which will come back to bite us shortly.
Arc-length parameterization
I said above my explanation of the tangent and normal are subtly wrong. The problem is the tangent and the normal should be inherent properties of the curve, regardless of how you represent it.
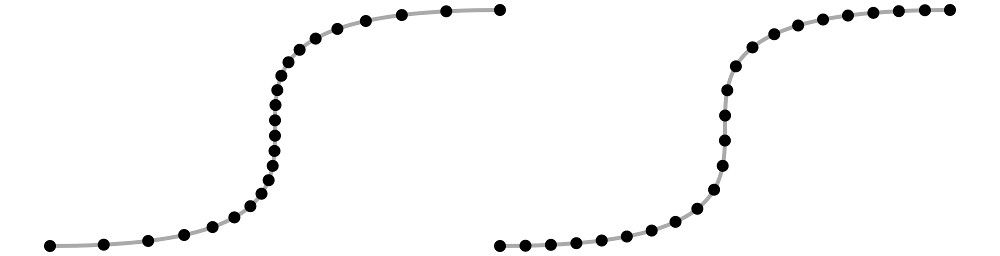
That means the tangent and the normal are generally represented based on the arc-length parameterization, and the calculations above only work under this parameterization. Intuitively, we need to sample points evenly spaced along the curve, as seen in the visualization below:
The time and arc-length parameterizations of the same curve
On the left, because of how the curve is defined (as a cubic Bézier curve), sampling at “evenly-spaced” intervals causes our samples to bunch up in the middle. This basically means the curve is moving slower near the middle and faster near the ends. What we actually want to do is pick samples that end up evenly-spaced, like on the right side. We want curve to move at the same speed all throughout.
Unfortunately, generating the arc-length parameterization is not easy to do in general. Luckily, for the applications I’m talking about, it doesn’t matter! If we take enough samples, the samples will be close enough that the finite differences approximation will work out. One caveat is that when computing the normal, you need to normalize the tangent vectors first. Remember, in the arc-length parameterization, samples are evenly-spaced, meaning the tangent is always a fixed length. Only then is the normal the derivative of the tangent.
The Frenet-Serret frame
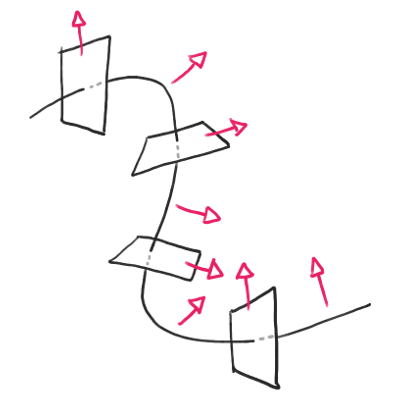
If you want to render a 1D curve as a 3D model, you need an orientation for the various cross sections. For example, if you’re describing a snake as a curve, you need a direction that counts as “up”. You can see this in the image below:
A 3D rendering is a series of cross sections along a curve, all of which require an orientation.
So, how do you define the orientation of the cross sections? Well, you need one vector that’s perpendicular to the tangent. That vector doesn’t need to be your “up” vector, as long as it’s always related in the same way to the “up” vector on each cross section. And, we have such a vector: the normal!
This observation is the key to the Frenet-Serret frame. To define an oriented plane in which a cross section will lie:
Start with the unit-length normal vector at the point in question. This is our reference vector.
Because the tangent is perpendicular to the cross section’s plane, you can take the cross product of the tangent and the normal ($\hat{\mathbf{t}} \times \hat{\mathbf{n}}$) to get another unit-length vector on the cross section’s plane. In fact, this vector will be perpendicular to the normal vector. Call this new vector $\hat{\mathbf{b}}$ for “binormal” vector.
Now, you have two vectors, $\hat{\mathbf{n}}$ and $\hat{\mathbf{b}}$ that define your plane, and you can orient your cross section accordingly. For example, you might just make the binormal vector your “up” direction.
Unfortunately, this is where we run into the problem with the normal vector suddenly flipping directions. If the curve has an inflection point, then the cross section will suddenly rotate $180^{\circ}$. You can see that in the following demo:
The Frenet-Serret frame suddenly flips orientation around an inflection point
Luckily, we can fix this problem using the Rotation Minimizing Frame or RMF. The paper Computation of Rotation Minimizing Frames goes over both the definition and an efficient calculation of the RMF, but intuitively:
Instead of using the normal as the reference vector, we want to choose a reference vector that doesn’t rotate around the tangent so much. In fact, formally, the ideal reference vector’s first derivative is in the same direction as the tangent, meaning the reference vector only moves along the tangent.
And, in order to be a reference vector for the cross section we care about, the reference vector has to remain perpendicular to the tangent.
As the paper explains, the RMF is defined by a set of Ordinary Differential Equations (ODEs), so finding the true solution is not trivial in general. Luckily, the algorithm presented in the paper is really easy to implement (I won’t go over the details here) and approximates the true solution really well. You can see how well the RMF behaves in the next demo:
The Rotation Minimizing Frame maintains its orientation
The only caveat here is we need an initial frame to start off the process. In the above demo, I’ve used the Frenet-Serret frame at $t = 0$, but in real applications, you’ll probably want to manually specify the initial frame. This is especially important for curves where the the normal is zero at the beginning of the curve because the curve starts off like a straight line.
Closed loops and torsion
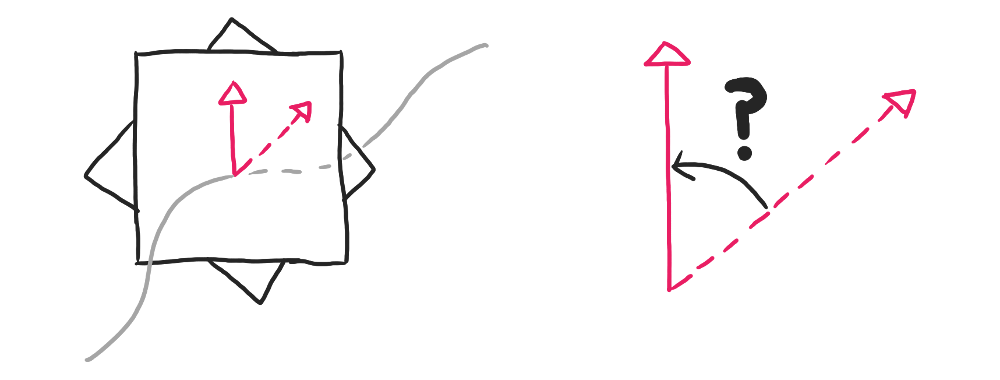
A curious thing can happen if the curve is a closed loop that doesn’t lie on one plane. Take a look at the following curve:
A non-planar curve might end up with misaligned ends
Even though the cross sections are created using Rotation Minimizing Frames, the starting and ending cross sections don’t line up with each other. In fact, I created this curve so that the starting and ending frames are exactly $180^{\circ}$ apart!
I’ll talk more about why this happens in later articles, as this very phenomenon was the subject of my research.
Technologies used
If you’re curious, I used the following technologies for the visualizations in this article:
Preact - a React-like DOM rendering library. Used for the 2D visualization, which reacts to the sliders.
three.js - a 3D rendering library that makes it easy to render WebGL content. It helped me to first understand WebGL (I even initially wrote all my rendering from scratch) before I started using an abstraction over it.
Unpkg for making it easy to import libraries from a CDN.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}