
Generating sequential IDs is common, like when assigning numbers to visitors. Photo by Pop & Zebra on Unsplash
Mar 23, 2020 • Avik Das
Generating sequential IDs is common, like when assigning numbers to visitors. Photo by Pop & Zebra on Unsplash
Working at scale has taught me some really interesting tricks. I want to start sharing some of them, so I’m starting a series on scalability concepts. To start off, let’s talk about a concept that comes up whenever you have servers distributed across multiple locations: distributed ID generation.
A common concept in database schemas is an auto-incrementing primary key. Let’s say your users are posting to some sort of feed, and each new post gets its own entry in the database. The standard way to model a post would be a posts table with the following columns:
id - a unique ID for each postauthor - a foreign key to the users tablebody, etc.The important constraint is that the ID is unique for each post, as you will often use the ID to reference the post (for example in the URL for the post detail page). So how do you enforce the uniqueness?
If you have one database server and one thread writing to the database, it’s easy. Make your IDs integers starting at zero. Each time you write a new post, check the highest numbered ID that’s present, and assign the new post an ID that’s one higher.
The moment you have multiple threads, you have a problem. Two threads read the same highest numbered ID, then one thread writes the next ID, and finally, the second thread writes the same ID! This is a common race condition, and in this single machine scenario, you can solve it by using locking. A lock ensures one thread will read and write an ID atomically, without any other thread coming in and writing an ID in the middle of this process.
Databases are good at this, and you can simply make the ID an auto-incrementing integer. The database will handle locking internally.
An auto-incrementing ID works fine as long as you have a single database, even if you have multiple application servers writing to the database. After all, it’s the database generating the ID, and there’s only one database. I want to point out: a single database architecture will take you far, so don’t prematurely try to scale!
Once your database becomes big enough that you want to distribute it across multiple machines, you have a problem: each database will have its own set of IDs that overlap. If you now consider all the posts across all the databases as one big collection of posts (I won’t go into how that’s achieved in this post), you won’t know which post is identified by a given ID. To truly keep your IDs separate, you have a few options.
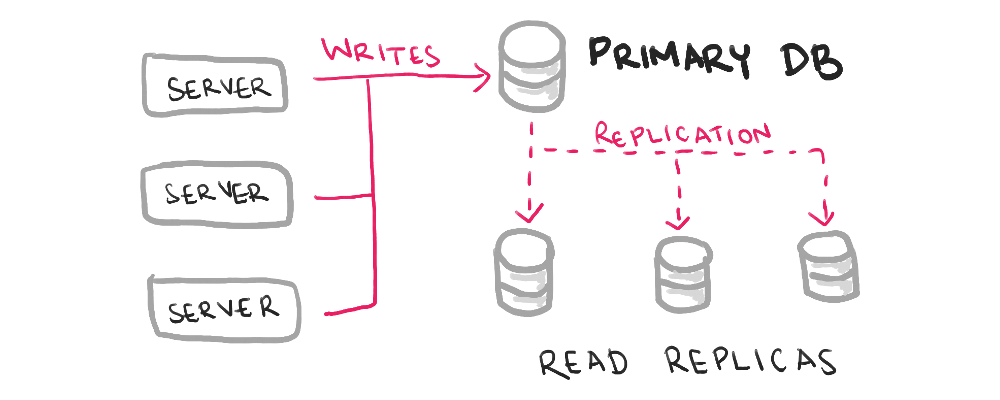
Even with multiple databases, you can have one designated database for writes. Often, this is implemented as a read replica, where all but the central database are used to offload read traffic.
The downsides are a single bottleneck, and potential replication delays when reading from your read replicas. However, if you read significantly more than you write, this architecture can work.
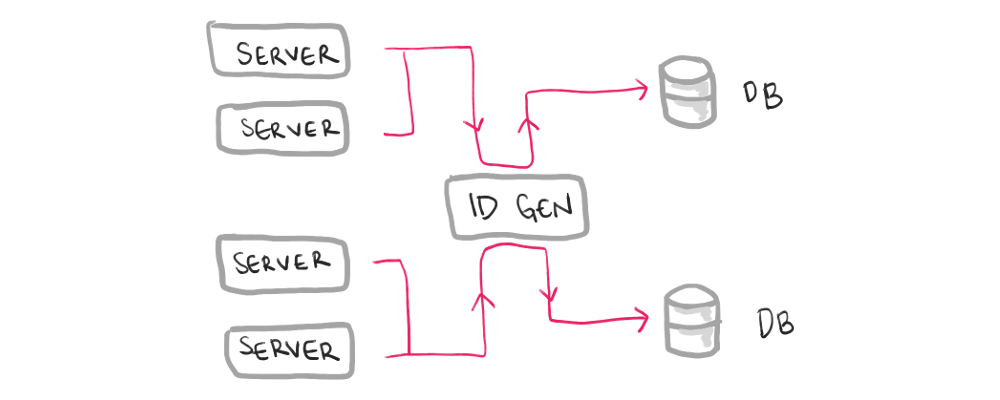
You write to any database, but before you do the write, you use a separate service to claim an ID for the new post. After claiming an ID, no other post can use that ID, even if that first post is delayed or not even succeeded due to an error after the ID generation.
While this lets you have multiple writable databases, you still have a bottleneck and an additional service to manage in your backend.
Instead of using strictly increasing IDs, pick a random ID from a large range. The trick is the range has to be very large. The most common example is a Universally Unique Identifier (UUID), which is a 128-bit number, meaning you’re picking from 2128 numbers. With that many possibilities and the right UUID generation technique, you’re essentially guaranteed a unique number every time you pick.
The downside is that the IDs are large and non-sequential, though the latter may be a good thing for security.
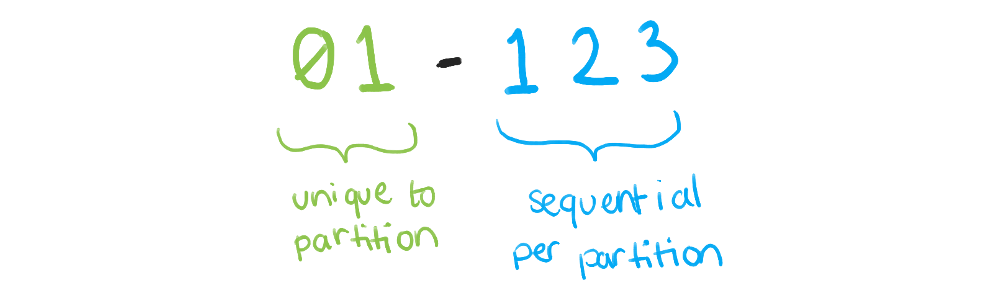
If you don’t want such large IDs (one example is generating IDs that can be easily written down for sharing), you can encode the partition in the ID. Give each database a unique prefix, like 00 and 01, and then that database always generates IDs with that prefix attached. Each database might generate IDs sequentially, then attach the prefix, and no other database would end up with the same final ID.
The downside is if you only have a few partitions, you might waste a few digits of your ID. It may also seem like this prevents removing or resizing partitions, but if you ensure any partition can read any data (again, a topic for another post), you probably won’t have any issues.
The last option is to not generate an ID, but to use the data itself as an ID.
While it may not make sense for the example of a post, consider “likes” on a post. It’s possible you may use a combination of the “liker” user ID and the post ID (previously generated with one of the above approaches) as the ID for the “like”. Because one user can like a particular post only once, this composite ID is guaranteed to be unique for each like in the system.
Often, scalability becomes a real problem when you start maintaining multiple data centers in different geographical locations. Cross data center calls, as would be required for centralization of any part of your architecture, becomes really expensive.
Luckily, you can often employ a non-centralized approach to avoid collisions between data centers, while using a centralized approach within a single data center, if that makes sense for your application.
It’s straightforward to ensure unique IDs when you have only one database, but as your application scales, you have to think about IDs differently. You can either find a way to generate IDs in a centralized manner, or generate them in a way that each database’s IDs don’t collide with the others.
Thanks to Ty Terdan